Status Page Grafana - MessMass
Ce projet a été réalisé durant mon stage de fin d'études au sein de l'équipe MessMass de Michelin. La problématique était simple à formuler, mais compliquée à vivre au quotidien : les autres équipes IT manquaient de visibilité sur l'état réel des middleware, et ouvraient souvent des tickets sans savoir si le problème venait de leurs applications… ou de chez nous.
J’ai donc conçu et développé une status page Grafana permettant de surveiller en temps réel les middleware critiques, de visualiser leur historique d’incidents et de donner aux équipes consommatrices une réponse immédiate à la question : « Est-ce que le problème vient de l’infrastructure MessMass ou de mon périmètre ? »
Contexte et objectifs
Dans le cadre du programme OneSystem IT Platforms, l’équipe MessMass devait améliorer l’observabilité de ses middleware (EDA, MFT, EAI, IFE/M2I, ETL) et réduire le nombre de tickets « pour rien ». La status page devait :
- offrir une vision synthétique et fiable de l’état des services pour les autres équipes IT ;
- permettre d’identifier rapidement si un incident vient d’un middleware ou d’un consommateur ;
- regrouper au même endroit statut, historique d’incidents et indicateurs de qualité de service ;
- s’intégrer naturellement dans l’écosystème existant (Grafana, Prometheus, ServiceNow).
Mon rôle
Grafana venait tout juste d’être introduit chez Michelin au moment de mon arrivée. J’ai dû apprendre à maîtriser l’outil de manière autonome et construire, itération après itération, une status page complète et maintenable qui serve de référence pour les futurs travaux Grafana au sein de l’entreprise.
- Conception de la structure globale de la page (domaines, services, indicateurs, navigation).
- Configuration des métriques dans Prometheus et intégration de plusieurs exporters (Blackbox, OpenTelemetry, scripts custom).
- Création des panneaux Grafana (Canvas, tableaux, cartes, indicateurs) et des requêtes PromQL.
- Intégration de données d’une autre équipe (API) avec un alternant, pour enrichir la vue globale.
- Rédaction de la documentation utilisateur/technique et d’un guide de standardisation graphique.
Fonctionnalités clés
- Monitoring en temps réel d’une quinzaine de middleware internes et externes via Prometheus et différents exporters (Blackbox, OpenTelemetry, scripts Python).
- Indicateurs visuels normalisés (OK/KO/Maintenance, couleurs, icônes) pour une lecture rapide.
- Historique des incidents avec liens directs vers les tickets ServiceNow et les pages de suivi SharePoint.
- Affichage des SLI et du burn rate des SLO pour comparer la performance aux objectifs.
- Fonction drill-down affichant la liste détaillée des composants et nœuds d’un middleware.
- Organisation par domaines fonctionnels (EDA, MFT, EAI, IFE/M2I, ETL) pour refléter la réalité métier.
- Intégration d’une API interne pour agréger des informations issues d’autres squads.
Architecture et mise en œuvre
La status page s'appuie sur une architecture d'observabilité unifiée :
- Prometheus collecte les métriques (disponibilité, erreurs, files d’attente, temps de réponse) via Blackbox Exporter, collecteurs OpenTelemetry, scripts Python et tests K6.
- Un service REST expose des données consolidées au format JSON pour certains périmètres.
- Grafana interroge ces sources et les présente dans des panneaux personnalisés (Canvas, tableaux, cartes, vues combinées).
Au fil des versions, l’interface est passée d’une simple vue binaire (up/down) à un tableau de bord structuré par domaines, combinant statut actuel, historique d’incidents et indicateurs de service dans une vue unique pensée pour les équipes utilisatrices.
Évolution et impact
Le développement s’est déroulé en plusieurs itérations : PoC basé sur Blackbox, ajout de statuts détaillés, structuration par domaines et enrichissement par les données des autres équipes. La version finale, validée par la squad HIP, est devenue un modèle de status page pour les futurs usages de Grafana chez Michelin.
Même si mon stage s’est terminé au moment de la mise en production, l’objectif est clair : réduire les tickets « inutiles », améliorer la compréhension de l’état des middleware par les équipes consommatrices et faciliter les diagnostics en centralisant l’information utile au même endroit.
Illustrations des versions
Afin de mieux visualiser l'évolution de la status page au cours des itérations, voici quelques captures d'écran représentatives des différentes versions du tableau de bord.
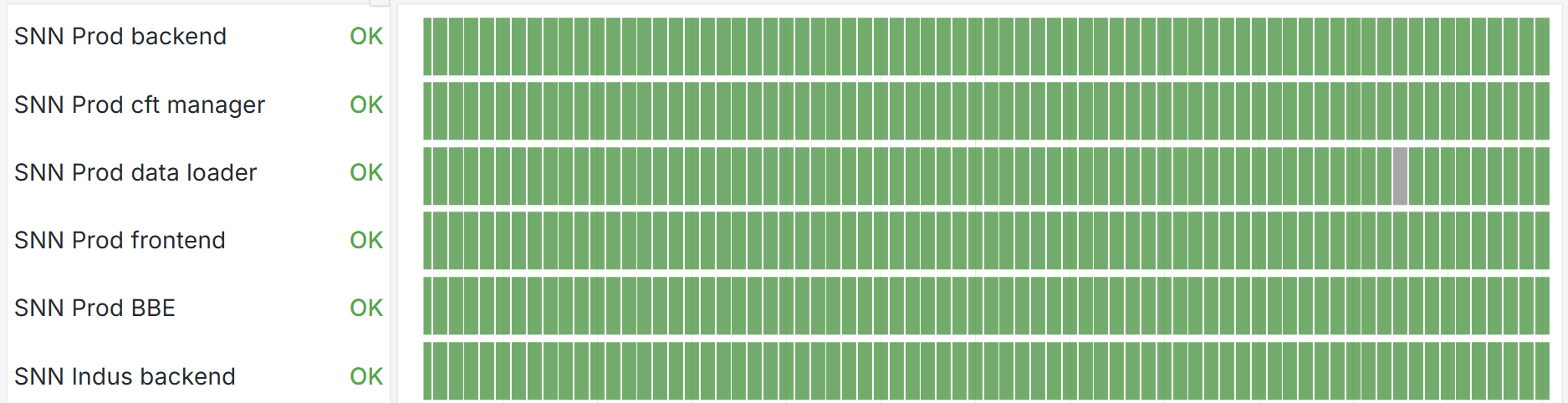
Version PoC
Première preuve de concept se limitant à la vérification de la disponibilité via le
Blackbox Exporter. Les statuts sont binaires (up/down) et l'interface très épurée.
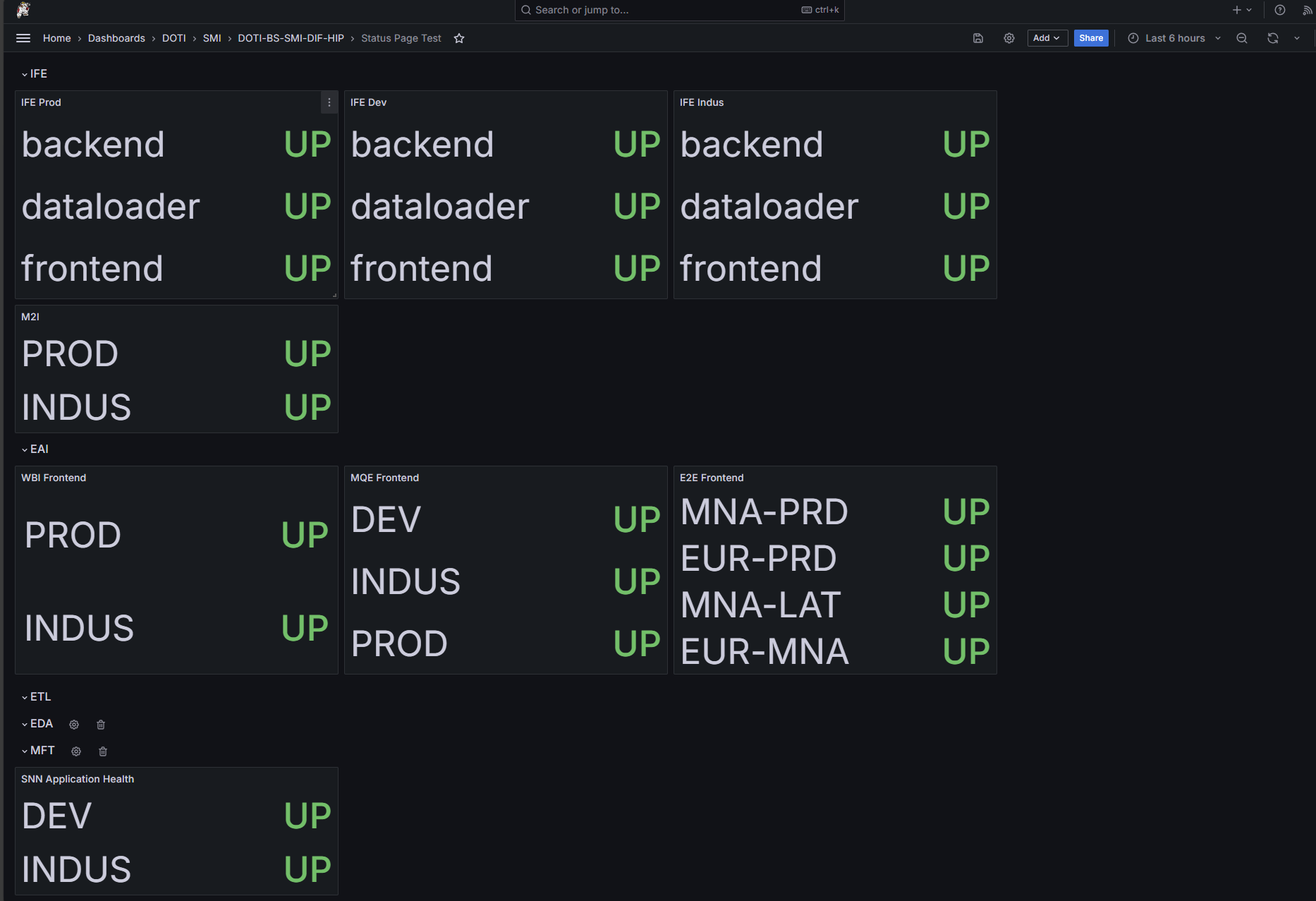
Première version
Introduction de cartes dynamiques pour chaque environnement (Prod, Dev, Indus).
La structure visuelle commence à refléter les usages des équipes.
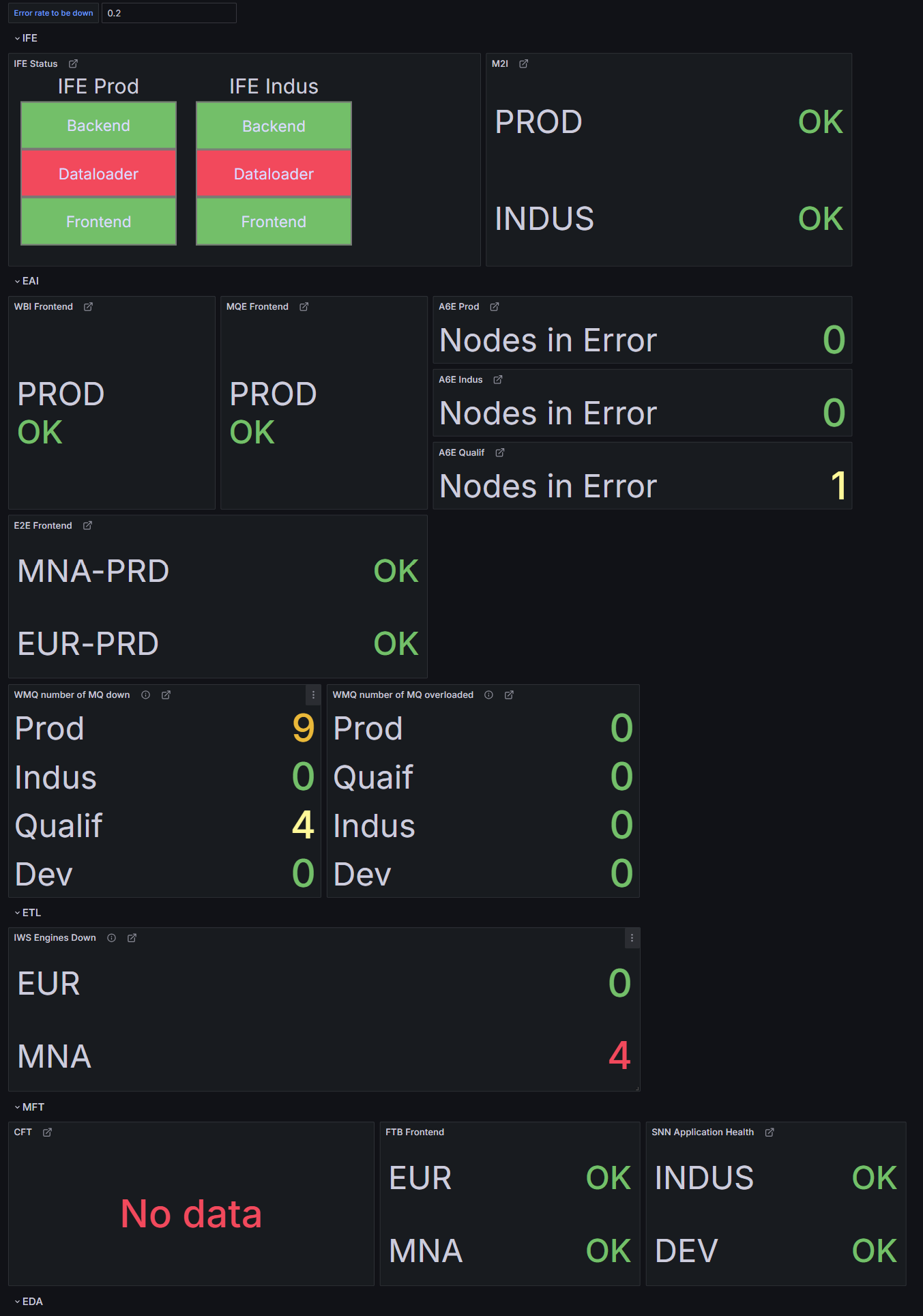
Version tests
Expérimentations sur les seuils, les codes couleur et l’organisation des blocs pour
trouver le bon compromis entre richesse d’information et lisibilité.
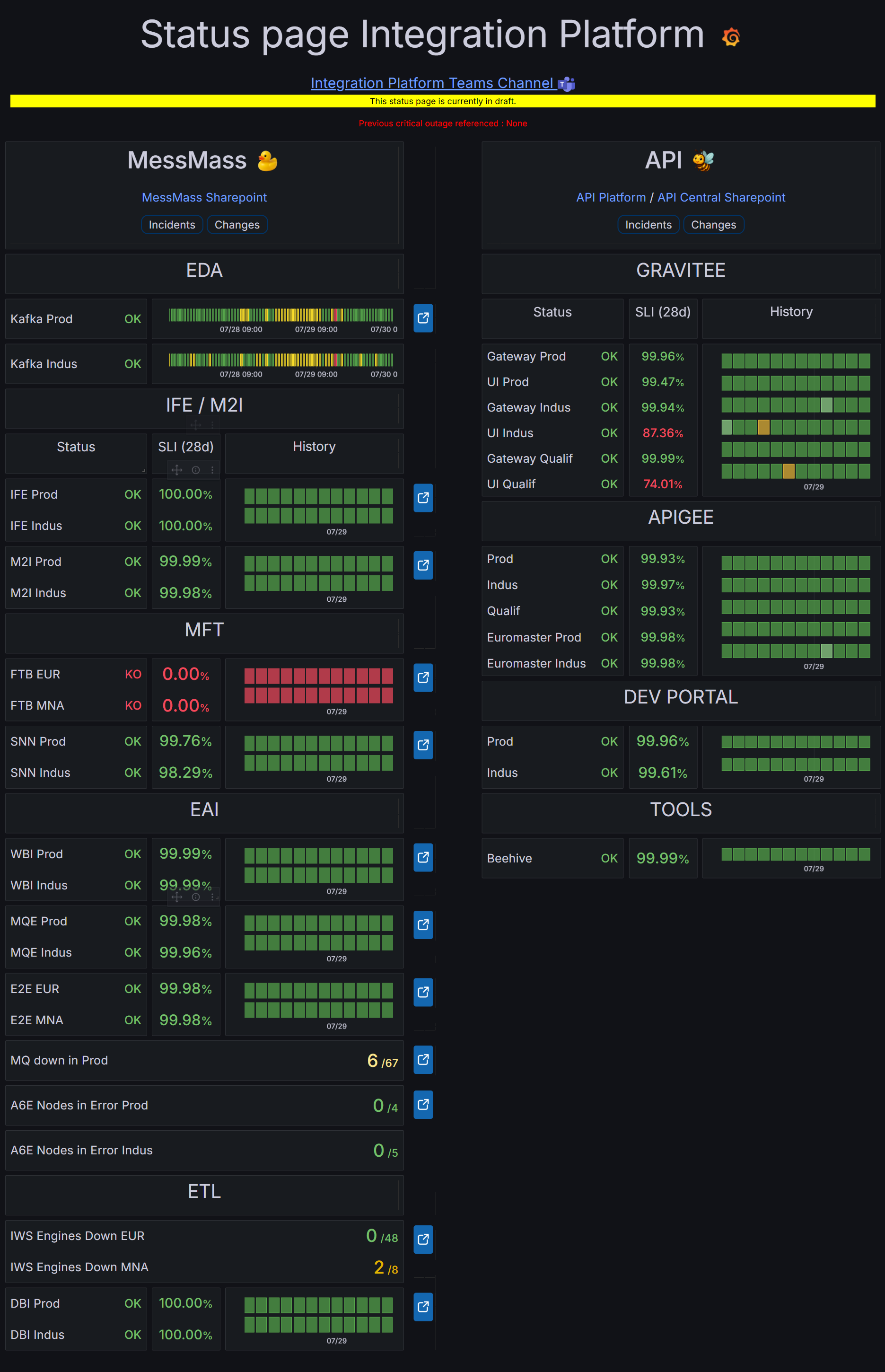
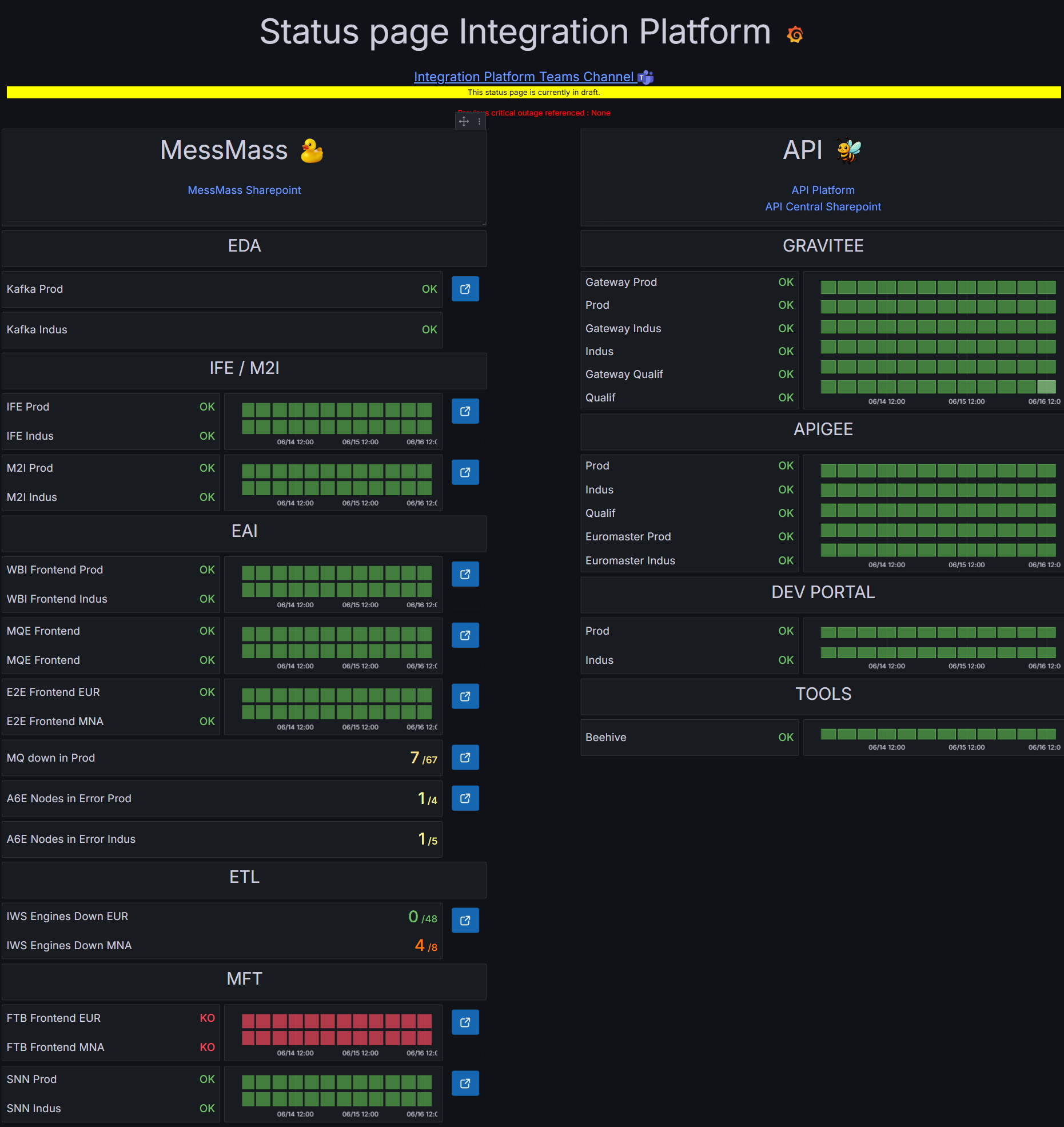
Version finale
Version validée par la squad, présentant les statuts, l'historique des incidents,
les indicateurs SLI/SLO et un bandeau d'informations pour chaque domaine
fonctionnel.
Notions utilisées
- Grafana pour la visualisation et l'agencement des panneaux (Canvas, tableaux, cartes).
- Prometheus et ses exporters (Blackbox, OpenTelemetry) pour la collecte et l'exposition des métriques.
- K6 pour les tests de charge et l'évaluation des temps de réponse des APIs.
- Python, Shell et API REST pour l'agrégation, la transformation et l'exposition des données.
- Rédaction de documentation utilisateur et technique, création d'un guide de charte graphique.